몬테카를로 트리탐색(MCTS)
2025. 1. 14. 14:34ㆍ알고리즘 문제풀이
몬테카를로 트리 탐색(Monte Carlo Tree Search, MCTS) 정리
MCTS의 개념
MCTS는 의사결정 문제를 해결하기 위한 탐색 알고리즘으로, 랜덤 시뮬레이션과 보상 기반 평가를 통해 상태 공간에서 최적의 행동을 추정합니다.
복잡한 상태 공간을 효율적으로 탐색하기 위해 설계되었으며, 턴 기반 게임, 경로 탐색, 강화 학습 등 다양한 분야에서 사용됩니다.
MCTS의 동작 과정
- Selection (선택):
- 루트 노드에서 시작하여, UCT(Upper Confidence Bound for Trees) 공식을 사용해 가장 유망한 자식 노드를 선택.
- UCT 공식: UCT=WN+ClnTNUCT = \frac{W}{N} + C \sqrt{\frac{\ln T}{N}}
- WW: 해당 노드의 총 보상 (누적 승리 확률).
- NN: 해당 노드의 방문 횟수.
- TT: 부모 노드의 방문 횟수.
- CC: 탐험(Exploration)과 착취(Exploitation)의 균형을 조정하는 상수 (일반적으로 C=1.4C = 1.4).
- Expansion (확장):
- 선택된 노드에서, 아직 탐색되지 않은 행동(액션)을 수행하여 새 노드를 생성.
- Simulation (시뮬레이션):
- 새로 생성된 노드에서 랜덤 정책을 사용하여 게임을 종료 상태까지 진행.
- 종료 상태에서 보상을 계산:
- 예: 승리 = +1, 패배 = -1, 무승부 = 0.
- Backpropagation (역전파):
- 시뮬레이션 결과(보상)를 루트 노드까지 전달하며, 방문 횟수와 보상 값을 갱신.
- 부모-자식 간 번갈아 두는 구조에서는 보상이 반전(플러스/마이너스)됩니다.
MCTS의 특징
- 탐험과 착취의 균형:
- UCT 공식에서 탐험(아직 탐색되지 않은 노드)과 착취(가장 높은 보상 값의 노드)를 적절히 균형 있게 탐색.
- 랜덤 시뮬레이션 기반:
- 상태 공간의 모든 경로를 완전 탐색하지 않고, 랜덤 시뮬레이션을 통해 승리 확률을 추정.
- 반복(iterations):
- 반복 횟수가 많아질수록 더 정확한 결과를 도출.
- 제한된 시간 내에서 가장 유망한 행동을 빠르게 탐색 가능.
- 상태 공간의 확장성:
- 복잡한 상태 공간에서도 효율적으로 작동.
- 상태 공간이 클수록 반복 횟수를 늘려서 유망한 행동을 평가.
MCTS의 장단점
장점
- 효율성:
- 상태 공간의 모든 경우를 탐색하지 않고, 유망한 경로만 집중적으로 탐색.
- 일반성:
- 특정 문제 도메인에 종속되지 않으며, 다양한 게임 및 의사결정 문제에 적용 가능.
- 점진적 개선:
- 반복 횟수를 늘리면 탐색 정확도가 점차 높아짐.
- 탐험/착취 균형:
- 탐험과 착취를 균형 있게 수행하여, 초기에는 탐험하고 후반에는 착취에 집중.
단점
- 랜덤성의 한계:
- 초기 랜덤 시뮬레이션 결과에 따라 성능이 달라질 수 있음.
- 시간 복잡도:
- 반복 횟수와 상태 공간 크기에 따라 계산 시간이 크게 증가.
- 전략 부족:
- 기본 MCTS는 랜덤 시뮬레이션에 의존하므로, 복잡한 문제에서는 전략적인 보완이 필요.
MCTS와 탐색 효율
- 전체 탐색이 아닌 유망한 경로만 선택적 탐색:
- 예를 들어, 틱택토에서 모든 가능한 상태(36만 개)를 탐색하지 않고, 제한된 반복(예: 1000번)으로 유망한 경로만 평가.
- 탐험과 착취:
- 초기에는 모든 후보를 고르게 탐색(탐험)하고, 반복이 진행될수록 승리 확률이 높은 후보를 더 자주 탐색(착취).
MCTS의 주요 활용 사례
- 게임 AI:
- 바둑, 체스, 틱택토 등 턴 기반 게임에서 최적의 행동 계산.
- 예: 딥마인드의 AlphaGo에서 MCTS와 신경망을 결합.
- 경로 탐색:
- 로봇 경로 계획 및 장애물 회피.
- 복잡한 환경에서 유망한 경로를 탐색.
- 강화 학습:
- 정책 평가 및 행동 탐색.
- 복잡한 상태 공간에서 보상을 기반으로 최적 행동 학습.
- 의사결정 시스템:
- 제한된 자원과 불확실성이 높은 상황에서 최적의 결정을 추정.
MCTS를 개선하는 방법
- 반복 횟수 증가:
- 반복(iterations)을 늘리면 더 많은 경로를 탐색하여 정확도가 향상.
- 휴리스틱 활용:
- 단순 랜덤 시뮬레이션 대신, 문제 도메인에 특화된 휴리스틱(전략)을 적용.
- 병렬화:
- 병렬 처리를 통해 더 많은 시뮬레이션을 수행.
- 탐험 상수 조정:
- UCT 공식의 탐험 상수 CC를 조정하여 탐험과 착취 간 균형을 최적화.
- 정책 강화:
- 랜덤 정책 대신, 사전 학습된 정책이나 가치 함수를 결합하여 성능을 개선.
MCTS와 행동 트리의 비교
MCTS:
- 목적: 상태 공간에서 최적 행동을 학습적으로 탐색.
- 평가 방식: 보상 기반.
- 특징: 학습과 탐색을 결합, 불확실성이 높은 상황에 적합.
행동 트리(Behavior Tree):
- 목적: 로봇의 행동을 조건 기반으로 제어.
- 평가 방식: SUCCESS, FAILURE, RUNNING 상태 반환.
- 특징: 미리 정의된 로직 기반, 실시간 제어에 적합.
결론
MCTS는 확률 기반 탐색 알고리즘으로, 불확실한 상태 공간에서 효율적으로 작동합니다. 반복 횟수가 많아질수록 정확도가 높아지며, 행동 트리와 같은 고정된 제어 방식과는 다른 학습적 접근을 제공합니다. 로봇 경로 계획, 게임 AI, 강화 학습 등 다양한 분야에서 성공적으로 활용되고 있습니다.
예시(TicTacToe)
import tkinter as tk
import math
import random
############################
# 1. 틱택토 상태 정의
############################
class TicTacToeState:
"""
틱택토 게임의 상태를 관리하는 클래스입니다.
board: 0(빈칸), 1(X), 2(O) 로 구성된 1차원 리스트 (길이 9)
current_player: 현재 플레이어 (1 또는 2)
"""
def __init__(self, board=None, current_player=1):
if board is None:
self.board = [0]*9
else:
self.board = board[:]
self.current_player = current_player
def get_possible_actions(self):
"""
현재 보드에서 가능한 수(빈칸의 인덱스)를 리스트로 반환
"""
return [i for i, v in enumerate(self.board) if v == 0]
def perform_action(self, action):
"""
action(0~8 위치)에 현재 플레이어의 말을 두고,
플레이어를 교체한 새 상태를 반환
"""
new_board = self.board[:]
new_board[action] = self.current_player
next_player = 3 - self.current_player # 1 → 2, 2 → 1
return TicTacToeState(new_board, next_player)
def is_terminal(self):
"""
게임이 종료되었는지 확인 (누군가 승리했거나 무승부인지)
"""
if self.get_winner() != 0:
return True
# 보드에 빈칸(0)이 하나도 없으면 종료
return all(x != 0 for x in self.board)
def get_winner(self):
"""
승자를 확인
0: 아직 승자 없음 or 무승부
1: X의 승리
2: O의 승리
"""
lines = [
(0,1,2), (3,4,5), (6,7,8), # 가로
(0,3,6), (1,4,7), (2,5,8), # 세로
(0,4,8), (2,4,6) # 대각선
]
for (a, b, c) in lines:
if self.board[a] != 0 and self.board[a] == self.board[b] == self.board[c]:
return self.board[a]
return 0
def get_reward(self):
"""
시뮬레이션 결과를 바탕으로 보상을 계산.
- winner == (3 - self.current_player) 이면 직전에 둔 플레이어가 승리(+1)
- 상대방 승리 시 -1, 무승부 시 0
"""
winner = self.get_winner()
if winner == 0:
# 무승부거나 진행 중
return 0
elif winner == (3 - self.current_player):
return 1
else:
return -1
############################
# 2. 노드 및 MCTS 알고리즘
############################
class Node:
"""
MCTS에서 사용하는 트리 노드 구조.
"""
def __init__(self, state, parent=None):
self.state = state
self.parent = parent
self.children = []
self.visits = 0 # 이 노드를 방문한 횟수
self.value = 0.0 # 누적 보상
def is_fully_expanded(self):
"""
이 노드가 표현하는 상태의 모든 가능한 액션이 자식 노드로 확장되었는지 확인
"""
return len(self.children) == len(self.state.get_possible_actions())
def best_child(self, c_param=1.4):
"""
UCB1(Upper Confidence Bound) 공식을 이용하여 최고의 자식 노드를 선택
"""
best_score = float('-inf')
best_node = None
for child in self.children:
# exploitation
exploit = child.value / (child.visits + 1e-9)
# exploration
explore = math.sqrt(
2 * math.log(self.visits + 1) / (child.visits + 1e-9)
)
score = exploit + c_param * explore
if score > best_score:
best_score = score
best_node = child
return best_node
def rollout_policy(possible_moves):
"""
시뮬레이션(rollout) 시 무작위로 액션을 선택하는 정책
"""
return random.choice(possible_moves)
def rollout(state):
"""
시뮬레이션 단계:
게임이 종료될 때까지 랜덤하게 액션을 수행한 뒤, 최종 보상을 반환
"""
current_state = state
while not current_state.is_terminal():
possible_moves = current_state.get_possible_actions()
action = rollout_policy(possible_moves)
current_state = current_state.perform_action(action)
return current_state.get_reward()
def backpropagate(node, reward):
"""
시뮬레이션 결과(보상)를 루트까지 거슬러 올라가며 누적
- 틱택토에서는 부모와 자식이 플레이어가 달라서,
backpropagate를 올라갈 때마다 보상 부호를 반전(-)해준다.
"""
current_node = node
while current_node is not None:
current_node.visits += 1
current_node.value += reward
reward = -reward
current_node = current_node.parent
def expand(node):
"""
선택된 노드에서 아직 탐색되지 않은 액션이 있다면, 새 자식 노드를 만들어 확장.
"""
actions = node.state.get_possible_actions()
existing_states = [child.state.board for child in node.children]
for action in actions:
new_state = node.state.perform_action(action)
if new_state.board not in existing_states:
new_node = Node(new_state, parent=node)
node.children.append(new_node)
return new_node
# 확장할 자식이 없으면 그대로 리턴
return node
def mcts(root, iterations=1000):
"""
MCTS 알고리즘을 반복적으로 실행
"""
for _ in range(iterations):
# 1. Selection
node = root
while node.is_fully_expanded() and not node.state.is_terminal():
node = node.best_child()
# 2. Expansion
if not node.state.is_terminal():
node = expand(node)
# 3. Simulation
reward = rollout(node.state)
# 4. Backpropagation
backpropagate(node, reward)
# 착취(exploitation)만 고려해 가장 가치가 높은 자식을 반환
return root.best_child(c_param=0)
############################
# 3. GUI 구현 (Tkinter)
############################
class TicTacToeGUI:
def __init__(self, master):
self.master = master
self.master.title("MCTS Tic-Tac-Toe")
# 폰트 등 설정
self.button_font = ("Arial", 24)
self.info_font = ("Arial", 14)
# 초기 상태: 플레이어1(X)부터 시작
self.root_node = Node(TicTacToeState(current_player=1))
self.current_state = self.root_node.state
# GUI 위젯 구성
self.frame_board = tk.Frame(self.master)
self.frame_board.pack(padx=10, pady=10)
self.buttons = []
for row in range(3):
row_buttons = []
for col in range(3):
btn = tk.Button(
self.frame_board,
text=" ",
font=self.button_font,
width=3,
height=1,
command=lambda r=row, c=col: self.handle_click(r, c)
)
btn.grid(row=row, column=col, padx=5, pady=5)
row_buttons.append(btn)
self.buttons.append(row_buttons)
self.label_info = tk.Label(self.master, text="당신은 X 플레이어입니다. 수를 두세요!", font=self.info_font)
self.label_info.pack()
self.button_reset = tk.Button(self.master, text="Reset Game", command=self.reset_game)
self.button_reset.pack(pady=5)
self.update_board()
def handle_click(self, row, col):
"""
유저가 (row, col)을 클릭했을 때 호출되는 함수
"""
index = row * 3 + col
if self.current_state.is_terminal():
return # 게임이 이미 끝난 상태라면 클릭 무시
if self.current_state.board[index] != 0:
return # 이미 둔 자리라면 클릭 무시
# 1) 사용자(사람) 수 두기
self.current_state = self.current_state.perform_action(index)
# 루트 노드는 사람의 수가 반영된 새 상태로 갱신
self.root_node = Node(self.current_state)
self.update_board()
# 만약 사람이 수를 둔 뒤 바로 게임이 종료되었는지 확인
if self.current_state.is_terminal():
self.check_game_over()
return
# 2) AI(MCTS) 수 두기
self.ai_move()
def ai_move(self):
"""
AI가 MCTS를 통해 수를 두는 과정
"""
best_child = mcts(self.root_node, iterations=1000)
self.current_state = best_child.state
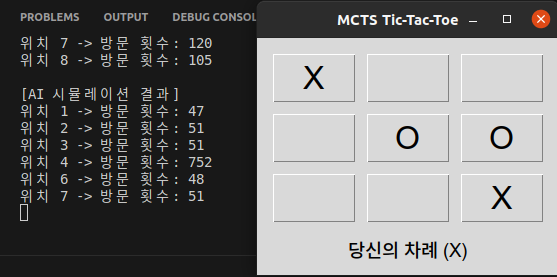
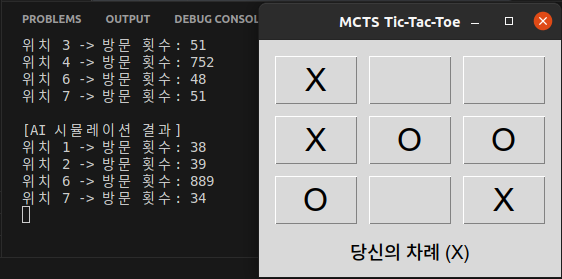
# 각 후보 위치의 방문 횟수 출력
print("\n[AI 시뮬레이션 결과]")
for child in self.root_node.children:
# 부모 상태와 자식 상태의 차이를 통해 액션 위치를 계산
for i in range(len(self.root_node.state.board)):
if self.root_node.state.board[i] == 0 and child.state.board[i] != 0:
action_index = i
print(f"위치 {action_index} -> 방문 횟수: {child.visits}")
break
# 컴퓨터가 선택한 위치와 방문 횟수 출력
for i in range(len(self.root_node.state.board)):
if self.root_node.state.board[i] == 0 and best_child.state.board[i] != 0:
action_index = i
# print(f"위치 {action_index} -> 방문 횟수: {best_child.visits}")
break
self.update_board()
# AI가 수를 둔 뒤 게임 종료 여부 확인
if self.current_state.is_terminal():
self.check_game_over()
def update_board(self):
"""
내부 state에 맞춰서 GUI 보드를 갱신
"""
symbols = [" ", "X", "O"]
for i in range(9):
r, c = divmod(i, 3)
val = self.current_state.board[i]
self.buttons[r][c].config(text=symbols[val])
# 현재 플레이어를 안내
if not self.current_state.is_terminal():
if self.current_state.current_player == 1:
self.label_info.config(text="당신의 차례 (X)")
else:
self.label_info.config(text="AI( O ) 생각중...")
else:
self.check_game_over()
def check_game_over(self):
winner = self.current_state.get_winner()
if winner == 1:
self.label_info.config(text="X 승리!")
elif winner == 2:
self.label_info.config(text="O 승리!")
else:
self.label_info.config(text="무승부!")
def reset_game(self):
"""
게임을 리셋하고 새 게임을 시작
"""
self.root_node = Node(TicTacToeState(current_player=1))
self.current_state = self.root_node.state
self.update_board()
self.label_info.config(text="당신은 X 플레이어입니다. 수를 두세요!")
############################
# 4. 실행 메인
############################
if __name__ == "__main__":
root = tk.Tk()
app = TicTacToeGUI(root)
root.mainloop()

'알고리즘 문제풀이' 카테고리의 다른 글
| 백준 1966번 문제 풀이 (0) | 2022.12.06 |
|---|---|
| 백준 1920번 문제 풀이 (0) | 2022.12.06 |
| 백준 1904번 문제 풀이 (0) | 2022.12.06 |